Have you ever wished you could watch your favorite videos in high definition, even if they were originally recorded in lower quality? Well, now you can, thanks to a new feature we are experimenting with in Edge Canary: video super resolution (VSR).

Video super resolution uses machine learning to enhance the quality of video viewed in Microsoft Edge by using graphics card agnostic algorithms to remove blocky compression artifacts and upscale the video resolution, so you can enjoy crisp and clear videos on YouTube and other video streaming platforms without sacrificing bandwidth.
Due to the computing power required to upscale videos, video super resolution (VSR) is currently offered when the following conditions are met:
- The device has one of the following graphics cards (GPUs): Nvidia RTX 20/30/40 series OR AMD RX5700-RX7800 series GPUs. [1]
- The video is played at less than 720p resolution.
- The device is not on battery power.
- Both the height and width of the video are greater than 192 pixels.
- The video is not protected with Digital Rights Management technologies like PlayReady or Widevine. Frames from these protected videos are not accessible to the browser for processing.
[1] Note: We are working on automatic Hybrid GPU support for laptops with multiple GPUs. Meanwhile, you can try VSR by changing Windows settings to force Edge to run on your discrete GPU.
Video super resolution is automatically enabled by Edge and indicated by an HD icon on the address. The feature can be computationally intensive, so this icon allows a user to be in full control of enabling or disabling the feature.

Availability
As noted above, we’ve started experimenting with a small set of customers in the Canary channel and will continue to make this feature available to additional customers over the coming weeks. We are also looking forward to expanding the list of supported graphics cards in the future.
Behind the Scenes
Let’s go into some additional details about how video super resolution, or VSR, works behind the scenes.
ONNX Runtime and DirectML
VSR in Microsoft Edge builds on top of ONNX Runtime and DirectML making our solution portable across GPU vendors and allowing VSR to be available to more users. Additional graphics cards which support these technologies and have sufficient computing power will receive support in the future. The ONNX Runtime and DirectML teams have fine-tuned their technology over many years, resulting in VSR making the most of the performance and capabilities of your graphics card’s processing power. ONNX Runtime handles loading ML models packaged as an .onnx files and uses DirectML, which handles the optimization and evaluation of the ML workload by leveraging the available GPU capabilities such as the native ML tensor processing to achieve the maximum execution throughput at a high framerate.
Storing Machine Learning Models
To preserve disk space, the components and models that VSR requires are only added to your device when we detect a compatible GPU. The presence of a component named “Edge Video Super Resolution” when visiting edge://components/ in Edge Canary is a signal that your GPU is supported by the video super resolution feature. This component-based approach lets us ship specific and multiple models based on device capability and performance.
DirectX 11 Interop with DirectML
To support VSR, we have built a new DX12 presentation pipeline in Microsoft Edge. Chromium, which Microsoft Edge is built on, uses DX11 for video decode/rasterization and generates DX11 textures after video decode. DirectML on the other hand only works with DX12 buffers. To support VSR, we built a new flexible DX12 pipeline into the Chromium engine that’s embedded in Microsoft Edge. Our new pipeline runs the shaders to convert DX11 textures into DirectML buffers/tensors for use with ONNX Runtime.
Enable or Disable Video Enhancement
Video super resolution can be disabled at any time by clicking the HD icon in the address bar and selecting the toggle for Enhance Videos:
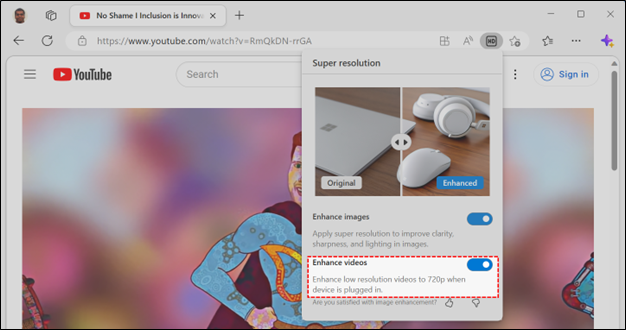 Turning off video super resolution persists for all sites in Edge preferences. This will also restore any video super resolution features supported by the graphics card driver on your system. To change your preferences for the feature or provide feedback, you can find the toggle and the feedback buttons by navigating to
Turning off video super resolution persists for all sites in Edge preferences. This will also restore any video super resolution features supported by the graphics card driver on your system. To change your preferences for the feature or provide feedback, you can find the toggle and the feedback buttons by navigating to edge://settings/system in your Edge browser.
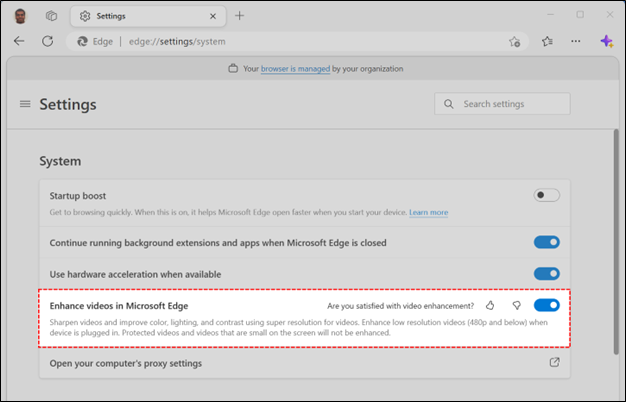 Video Quality Improvements
Video Quality Improvements
All the details above wouldn’t matter if we did not have great results. Let’s start with some comparisons of 360p videos with our current models:
Model Performance Metrics
The super resolution model in Edge is quite good at upscaling a wide range of content types without any artifacts. To fit the in the performance envelope of your GPU, we typically use this model for videos resolutions ≤ 360p. If you want to inspect the performance of our video super resolution sub-system, you can navigate to edge://histograms/Microsoft.Media.Video.SuperResolution in another tab after viewing a few seconds of video content. For example, on a Nvidia RTX 2060, inference on the 360p sample above took 20ms per frame:
Inference GPU time needs to be under 16ms for 60 FPS (1000ms/60frames) videos and under 33ms for 30fps video. To scale to higher resolutions and frame rate on this GPU, we have a separate, lighter model that we use for resolutions >360p.This lighter model shines at on screen text and improves sharpness and readability. The model is 10 times smaller than our heavier model and should allow us to improve a larger set of video resolutions and give us an opportunity to enable video super resolution on lower end devices in the future. The policy to switch between models and picking the right model for the device, video resolution, framerate is something that we are actively iterating on.
Machine Learning Models & Model Compression
The stars of the show are the machine learning (ML) models from Microsoft Research Asia (MSRA). These models were distilled and compressed from a much larger model by our partners on the Microsoft DeepSpeed team. In this section we’ll discuss some of the approaches that the ML model development teams took to build these models.
Model Training
Existing video super-resolution models aim to learn a mapping function that predicts high-quality (HQ) frames from their low-quality (LQ) or low-resolution counterparts. However, to generate low-quality/low-resolution frames for the training data set, most of these methods use predefined operators (e.g., bicubic down-sampling) to simulate the LQ input. This limits their general application on real-world video data, especially for streaming video data with high compression rates. In our approach, we take video compression into consideration and train our models with LQ-HQ video pairs that we synthesize by running several popular video codecs with different compression strategies.
Inspired by the recent success in large language models, MSRA pre-trained a base video enhancement model on one million video clips from diverse categories by a self-supervised LQ-HQ restoration paradigm. By further considering multiple types of video compression artifacts from different codecs, the ML model can significantly recover different video content with a large range of video degradation levels (e.g., CRF (Constant Rate Factor) values from 15 to 35 in H. 264). To improve the visual quality of the model, we take a two-stage training strategy in which the first stage aims to recover structure information (e.g., the edge and boundary of objects) while the second stage is optimized with perceptual and generative adversarial objectives for high-frequency textures (e.g., tree leaves and human hairs).
Loss Evaluation
Evaluation metrics in video enhancement tasks is another area we focused on. Existing metrics in this space like LPIPS (Learned Perceptual Image Patch Similarity) and FVD (Fréchet Video Distance) cannot fully reflect human perceptual preference. To better understand the performance of our models, MSRA team built an end-to-end pipeline for subjective evaluations of video enhancement tasks. Specifically, we ask participants to annotate their preferences for different methods on real-world video data from ten categories. The participants are asked to not only consider the static quality of each video frame but also take dynamic quality into account, which is more important for improving user experiences. The proposed pipeline shows that over 90% of users prefer our final models to the default bilinear upscaling in the browser.
Model Compression
The base machine learning models certainly improve visual quality over the traditional bilinear up-sampling methods, but the high compute cost makes real-time inference a challenge on common consumer GPUs. To overcome this, the DeepSpeed team applied state-of-art compression techniques to reduce the model size and inference cost.
The team used knowledge distillation and layer reduction from the XTC work and auto-pruning method from the LEAP work in DeepSpeed compression library to compress the model for Microsoft Edge device deployment. Edge provides two versions of the model, with the larger one having 10 times smaller model size (1MB) compared to the original base model and 5 times faster real-time inference on videos ≤ 360p in comparison to the original base model while still achieving over 95% win/on-par rate compared to the standard bilinear solution. The lighter version has an additional 10x reduction in model size (0.1MB) and 5x speedup on large resolution videos over the larger one with a 2x higher win-rate than the traditional bilinear baseline. By utilizing both models, we have broad real-time inference coverage for video super-resolution across GPU specs and video resolutions.
Video super resolution is an exciting feature that will make your video streaming experience more immersive and enjoyable. It will enhance the details and the beauty of your favorite content. We are working to improve the models and hardware coverage to provide better experience for even more users. Keep an eye out for updates from the team as we increase the availability to all Canary channel users over the coming weeks.
Source: Windows Blog
—